最初に見るべき結論
RAGを導入する前に、どの情報源を正本とするか、誰が所有するか、誰がアクセスできるか、回答でどう引用するか、情報が古いときにどう扱うかを決める必要があります。
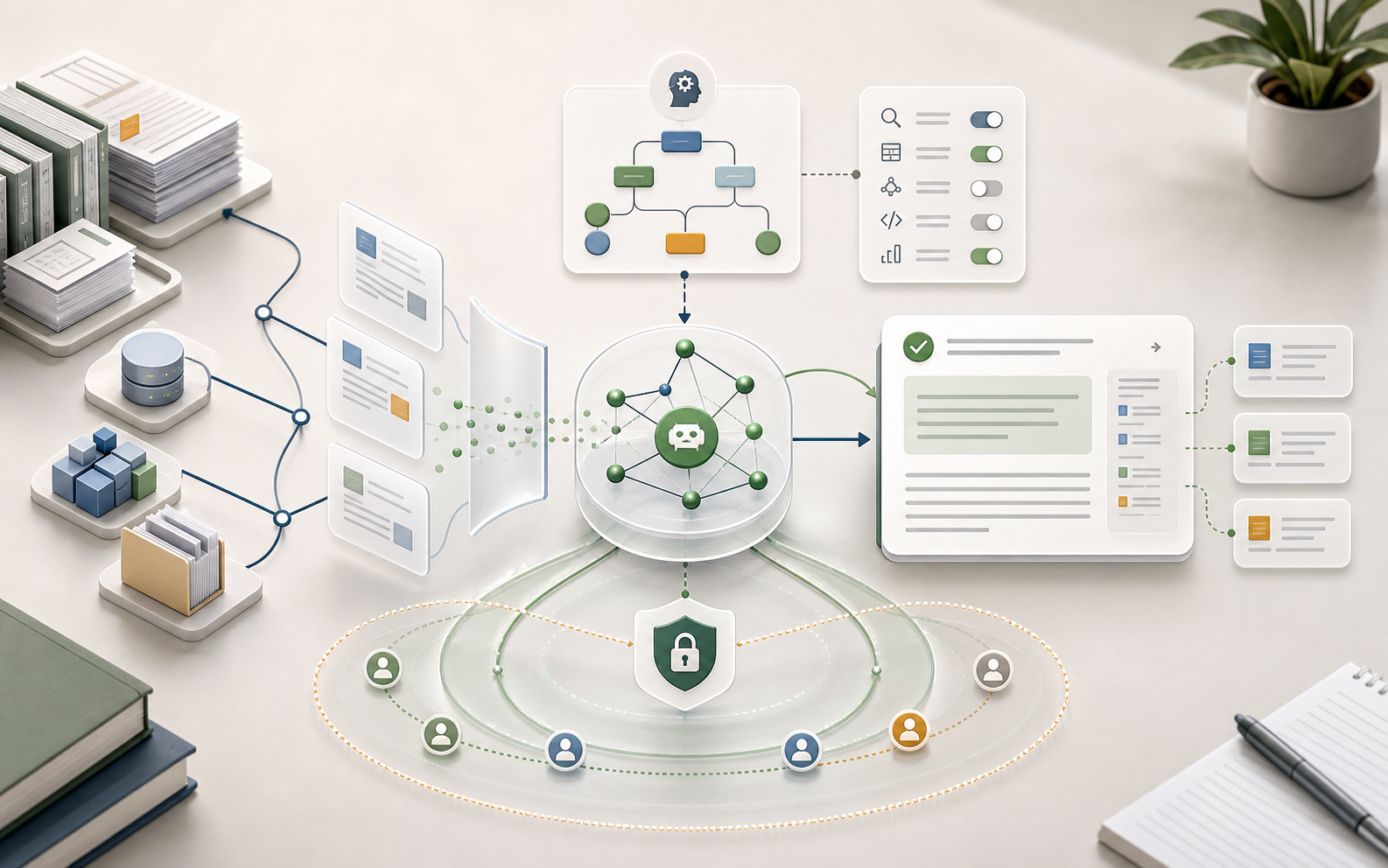
RAGは、単なるベクトルDB導入ではありません。企業の社内ナレッジ検索では、文書の所有者、権限、更新ルール、レビューの責任が重要になります。
最初の実装は、全社文書を対象にするより、1つの業務と承認済みの情報源に絞る方が安定します。
実装前チェックリスト
まず、よくある質問パターンを決めます。利用者が実際に聞く質問と、業務上必要な回答が見えていないと、検索精度を評価できません。
次に、情報源を棚卸しします。承認済み文書、ドラフト、古いファイル、個人メモ、顧客情報、閲覧制限のある資料を分けます。AI層が既存の権限を迂回しない設計が必要です。
最後に、回答の振る舞いを決めます。根拠を示す、確信度が低いときに止まる、人に引き継ぐ、あとで検証できるログを残す、といったルールが必要です。
| 確認項目 | 理由 |
|---|---|
| 質問セット | 検索品質を何で測るかを決めるため |
| 情報源の所有者 | 誰が更新し、承認するかを明確にするため |
| アクセスルール | AIが既存権限を迂回しないようにするため |
| 引用ルール | 利用者が回答の根拠を確認できるようにするため |
| 鮮度ルール | 古い規程や提案書を現在情報として扱わないため |
| 評価セット | 公開前後で同じ基準で改善を測るため |
Agentic RAGが必要になる場面
1回検索して答えるだけでは足りない業務では、Agentic RAGが有効になります。質問を分解し、複数の情報源を確認し、規程を比較し、必要に応じてツールを呼び出し、根拠が足りなければ止まる、といった動きが必要になるためです。
ただし、最初から複雑なエージェントにする必要はありません。まずは検索、引用、権限、評価を安定させ、業務上必要な部分だけに計画やツール利用を足します。
基本の回答が信頼できる状態になってから、自律性を高めるのが現実的です。
次の一歩
社内ナレッジ検索を作るなら、まず情報源の棚卸しと、実際の質問セットを作ります。この2つがあると、RAGの設計と評価が具体化します。
実業務からRAGを設計する
Atlas Supportは、情報源の所有者、アクセス境界、引用、評価テスト、最初の業務範囲を整理し、社内ナレッジ検索AIの導入を支援します。